
Transitive Closure in PostgreSQL
At Remind we operate one of the largest communication tools for education in the United States and Canada. We have...

The Remind OpsEng team has “Open Sourced” our monthly status reports. This post briefly describes some of the bigger tasks and projects we have worked on over the past month.
If you want us to elaborate on a specific topic, let us know!
Until now, we’ve primarily relied on Reserved Instances (RI) to minimize our EC2 spend. In the past month, we started experimenting with using Spot Instances to lower our costs even further.
To do this, we’re making use of an awesome little open source tool called autospotting. In a nutshell, it will automatically replace an on-demand instance in our ASG’s when a cheaper spot instance is available. Because our service architecture is heavily based around The Twelve-Factor App model, spinning up and tearing down instances is no problem for us, making spot instances a good fit.
With that said, moving to spot instances didn’t come without its challenges. Before using spot instances, we used c4.2xlarge instances almost exclusively. As part of our configuration, autospotting will select an “as good or better” instance type, which means we could have a c4.2xlarge replaced with a c3.2xlarge (equivalent CPU/memory), or m3.2xlarge (equivalent CPU, more memory). Because these instances use different CPU’s, we ran into some issues where a C extension in one of our Ruby applications was being compiled with CPU specific optimizations for c4.2xlarge instances, which would cause the application to crash when running on a c3 or m3. You can find more details in this github issue.
For well over a year, we settled on running Docker 1.11.x because of it’s overall stability, and our past experiences with upgrading Docker usually resulted in performance regressions. Since Docker rarely backports bug/security patches to older versions of Docker, we wanted to take a stab at upgrading to the latest Docker CE (Community Edition) version.
I’m happy to say that upgrading our ECS container instances from Docker 1.11 to Docker CE 17 was the smoothest Docker upgrade we’ve ever done.
We released a new version of Empire, which includes some new features and a number of improvements. We also wrote a blog post about the necessity of using Docker image digests, which Empire v0.13 has better support for.
As a result of some internal product development, the number of connections to our primary postgres database increased significantly, which resulted in us scaling out our PgBouncer cluster from 4 hosts to 8.
In the process, we noticed some odd CPU usage behavior on our pgbouncer hosts, where CPU usage would quickly spike, then drop down to 0%. Restarting pgbouncer processes removed the jigsaw pattern:
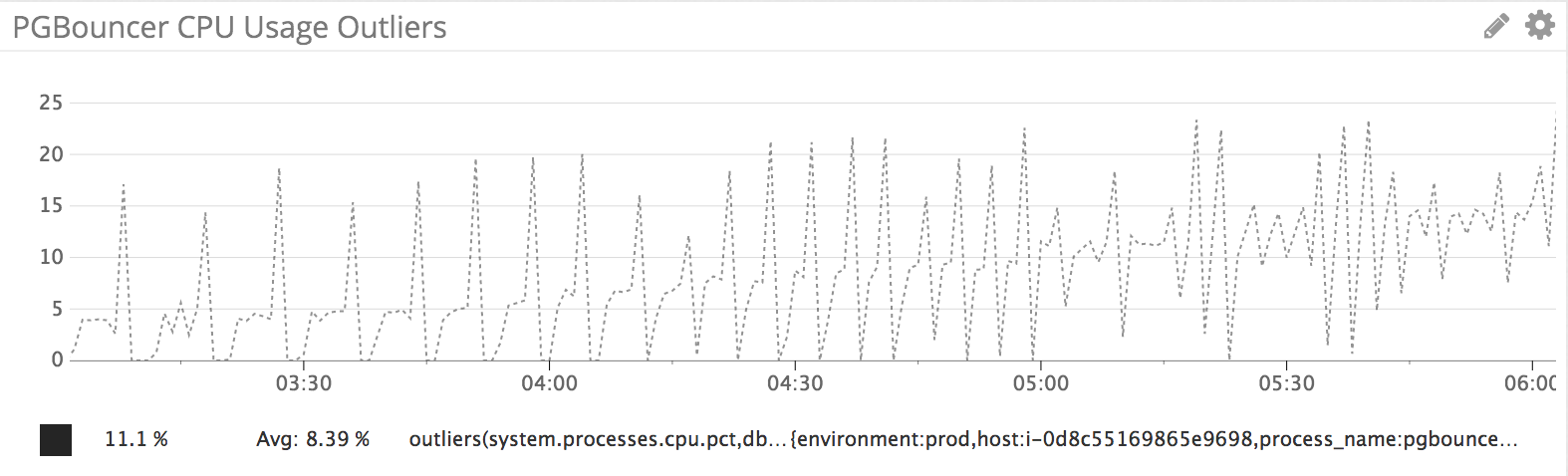
It appears that this doesn’t actually cause any noticeable performance issues, but the behavior is odd enough to warrant some investigation. If we find anything meaningful, we’ll probably write about it in a future post.
We spent some time refinding our EMR policies to make them more granular, and to fix some issues we discovered in CloudTrail.
We reviewed the default IAM policy permissions, and added it to our “developer” role so our data engineering team can play around with it. AWS having created such a granular default policy was a real time-saver; no need to hunt around permissions like we did for EMR.
We’ve used AWS Lambda in the Ops Eng team for various pieces of our infrastructure, like automatically draining ECS instances that are about to be terminated, but didn’t have a good workflow for our product engineers to use it. We’re working on developing some workflows that allow our developers to easily (and securely) deploy new lambda functions into production, by using stacker and CloudFormation. We’re making use of CloudFormations ability to use a passed role, which allows developers to provision resources with CloudFormation, without actually giving anybody other than CloudFormation the ability to create or destroy resources.

