
Transitive Closure in PostgreSQL
At Remind we operate one of the largest communication tools for education in the United States and Canada. We have...

Betterscaling was designed and implemented by Phil Frost. Phil was an exceptional engineer and a brilliant person, and he is dearly missed by all of us at Remind who knew him.
I had the privilege of interviewing Phil extensively about Betterscaling over the course of writing this article — much of it is in his own words. I hope that it will serve in some small way to reflect his expertise and dedication to his craft, and to stand as a tribute to his memory.
More students, teachers, and parents are relying on Remind’s free messaging features than ever, and although Remind is free for the majority of its users, serving those users still incurs costs. To keep Remind accessible to everyone, we’re constantly working to optimize our infrastructure in order to reduce unnecessary overhead.
As we dove into the data on our operating costs, we found that overprovisioned resources were a significant cost driver that was ripe for optimization. Specifically, in summer and fall of 2020, on average 20-30 percent of the CPUs in our cluster were provisioned but unreserved — processing power we were paying for, but not using.
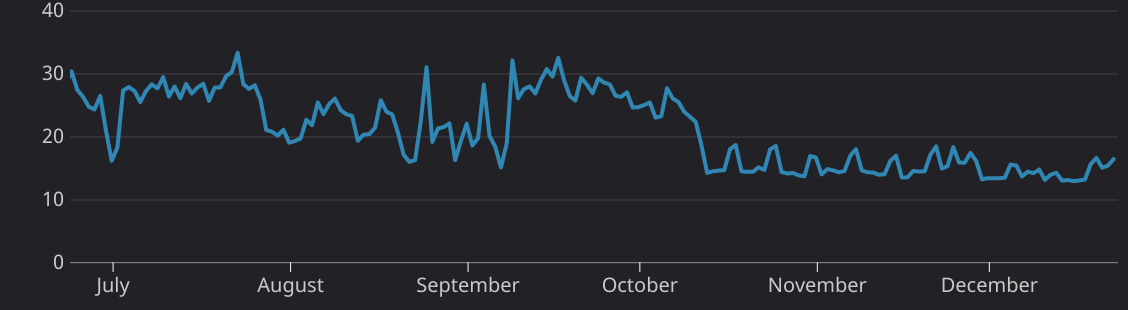
Percentage of unreserved CPU before and after Betterscaling (implemented in mid-October 2020)
Remind relies on AWS for our server infrastructure, and we found that this overprovisioning was mostly a result of inefficiencies in AWS autoscaling. This by no means an indictment of AWS autoscaling in general — we simply found that it wasn’t ideal for our use case, for reasons I’ll discuss in more detail below.
Instead, we developed a simple, lightweight autoscaling tool we’re calling Betterscaling. In a nutshell, Betterscaling evaluates a control loop which queries the ECS API to determine how big the cluster needs to be based on the tasks running in it, then manipulates the DesiredCapacity on an ASG to make the cluster that big. This article discusses how and why we decided to implement Betterscaling, and then dives into the mechanics of the system itself.
We now rely on Betterscaling to manage provisioning for our largest cluster, and as a result our average unreserved CPU has fallen from 30% to around 15% — a 50% reduction!
Nothing necessarily! In fact, we still use AWS autoscaling to manage our smaller clusters, and we even have a step-scaling policy in place as a fallback on the cluster that’s managed by Betterscaling. However, we found that while AWS autoscaling is easy to set up, it’s not as efficient as it could be when scaling on CPU reservation.
Before we dive in further, I’d like to clarify that this discussion of AWS autoscaling is intentionally limited to scaling on CPU reservation because that’s the specific problem that Betterscaling was designed to solve. AWS autoscaling does a great job of supporting the wide variety of things you might want to scale on, but our focus was on getting maximal performance in a single thing — CPU scaling — in order to solve our direct problem of having too much CPU throughout the day.
All AWS autoscaling is based on CloudWatch metrics, which have a maximum resolution of 1 minute. There is also a variable and unpredictable latency, typically between 90 seconds and 5 minutes, when querying for the most recent value of a metric. These delays are then compounded further by the time it takes to launch new instances, and by the cooldown period, which is required to avoid repeated scale-ups as new capacity is launching.
To illustrate the cumulative effect, here’s an example timeline:

With AWS autoscaling, it takes about 10 minutes after demand increases to trigger a scale-up action. Since it takes about 3 minutes to launch a new instance, that means we won’t be able to meet the added demand for at least 13 minutes. Additionally, there’s a 5-minute cooldown period before we can trigger additional scale-ups, which futher increases the lead time if we need to scale more than one instance.
By contrast, here is Betterscaling’s performance over the same timeline:

Since Betterscaling doesn’t have to wait for CloudWatch, its lead time is comparatively miniscule — about 10 seconds to fetch the cluster summary from ECS, and another 10 seconds to request new instances from the ASG. As a result, we can have new instances up and running less than 4 minutes after demand increases.
The latency inherent to CloudWatch means that AWS autoscaling is always reacting to how things were several minutes ago. Consequently, it will under-provision when demand is increasing, and over-provision when demand is decreasing.
To ensure application availability, the Auto Scaling group scales out proportionally to the metric as fast as it can, but scales in more gradually. — AWS autoscaling docs
By design, both AWS autoscaling and Betterscaling make it easier to add instances than to terminate them. This is a good thing in principle, as underprovisioning is hazardous to availability while overprovisioning is merely inefficient. However, we found that AWS autoscaling limits scale-in to the extent that it often can’t terminate instances fast enough to keep up with our CPU utilization targets when demand decreases.
The most significant of these limitations, in our experience, is that AWS autoscaling’s target tracking policy will only terminate one instance at a time when scaling in, even if it would need to terminate multiple instances in order to hit its target. There is no such limit in place when scaling out: AWS autoscaling will happily launch as many instances at once as it calculates are necessary to hit the target.
AWS autoscaling’s target tracking policy also requires three consecutive evaluations to scale out, but fifteen to scale in. On its own, this behavior is a useful safeguard, and in fact Betterscaling also requires more evaluations to scale in (a configurable number) than to scale out (just one). Together with autoscaling’s one-at-a-time limitation on scaling in, however, this means that terminating n instances takes AWS autoscaling a minimum of 5n times longer than launching the same number: ten times longer to terminate two instances than to launch two instances, fifteen times longer for 3 instances, and so on.
Lastly, any autoscaling solution must round to a whole number when it calculates how many instances to add or remove (since, of course, launching a fraction of an instance is impossible). Both Betterscaling and AWS autoscaling’s target tracking policy round up when scaling out and down when scaling in. With a step scaling policy, however, AWS autoscaling rounds up when scaling in — if the policy calculates that it should terminate 0.2 instances, for example, it will terminate 1 instance.
This might sound like it would facilitate scaling in faster (and thus mitigate overprovisioning), but in reality it has the opposite effect. Because it will always terminate at least one instance, it requires us to set the first scale-in threshold low enough that terminating one instance is always safe. And because that one instance represents a different percentage of capacity at different times of day, there’s no place to put this threshold which doesn’t either overprovision or terminate too much capacity sometimes.
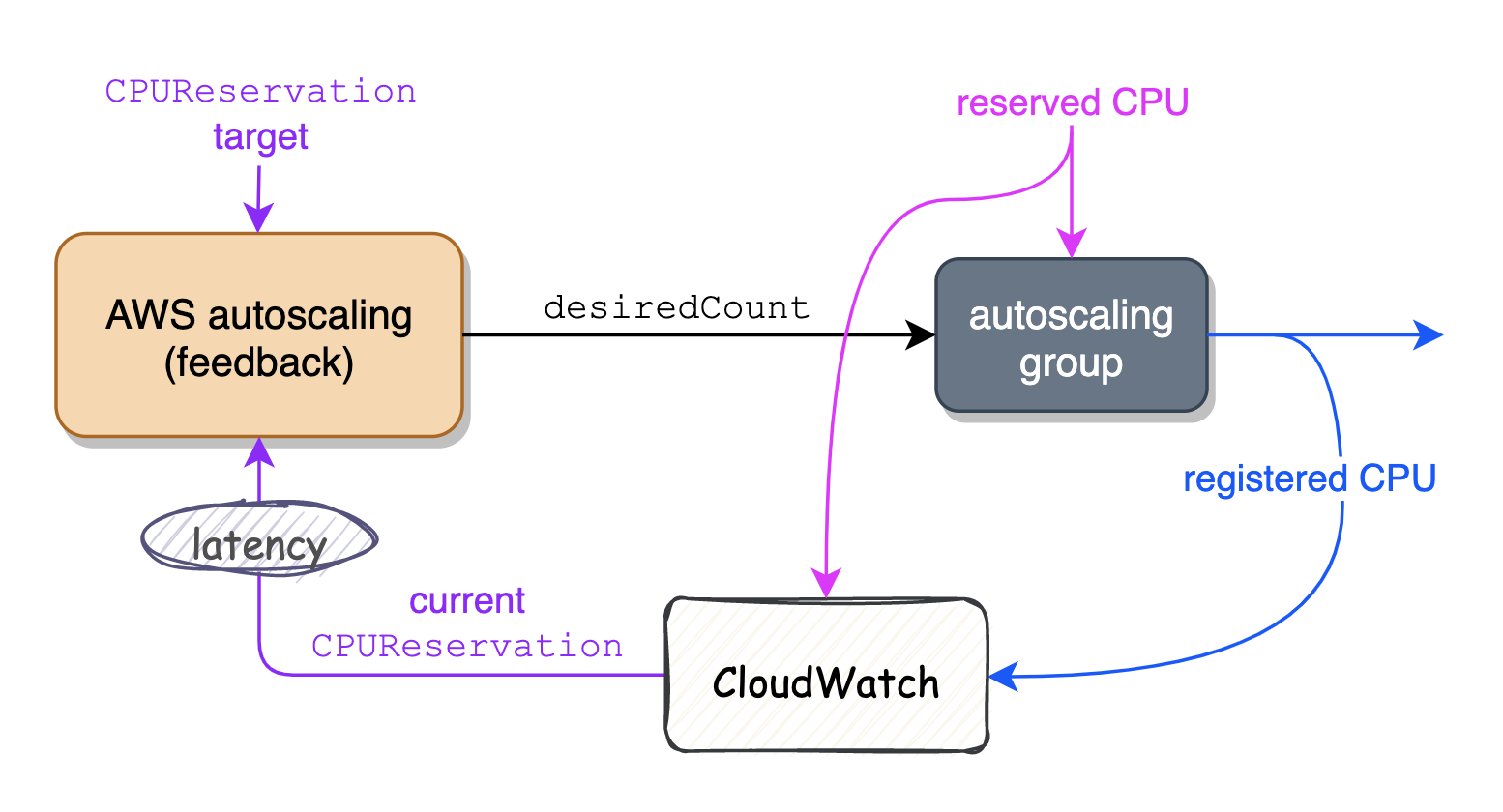
At Remind, we scale our clusters based on the CPU shares reserved by the tasks running on that cluster. AWS autoscaling has a metric for this called CPUReservation:
Each minute, Amazon ECS calculates the number of CPU units, MiB of memory, and GPUs that are currently reserved for each task that is running in the cluster. The total amount of CPU, memory, and GPUs reserved for all tasks running on the cluster is calculated, and those numbers are reported to CloudWatch as a percentage of the total registered resources for the cluster.
In other words, the CPUReservation metric is the percentage of CPU units currently reserved by tasks running on the cluster, out of the total number of CPU units currently registered in the cluster. Notably, the presence of registered CPU in this calculation means that CPUReservation is dependent on feedback from the cluster being controlled (since total registered CPU depends on the size of the cluster).
The main advantage of this approach is that autoscaling needs to know almost nothing about the cluster itself (eg, specific quantities of reserved or registered CPU) in order to scale it effectively — all it cares about is whether the current value of CPUReservation is above or below target. The corresponding downside is, of course, latency: after a scale event, AWS autoscaling must wait for the new instance to spin up, plus the delay inherent to CloudWatch, in order to obtain the latest value of CPUReservation.
On the other hand, if we know both how much CPU is reserved on our cluster (from ECS) and what kind of instances the cluster uses (hence how much CPU capacity per instance), we do not need to know the current registered CPU on the cluster in order to determine how much registered CPU we actually need. Instead, we can simply calculate the desired size of the cluster from the current reserved CPU and our percentage target. Since it relies on data external to the system being controlled, rather than feedback from that system, this approach is described as feed-forward.
Feed-forward scaling has two major advantages. First, because it doesn’t depend on feedback from the cluster, it can avoid the lag in information inherent to CloudWatch. And second, it guarantees stability of the control loop — since a purely feed-forward system has no loop, it can’t become unstable.
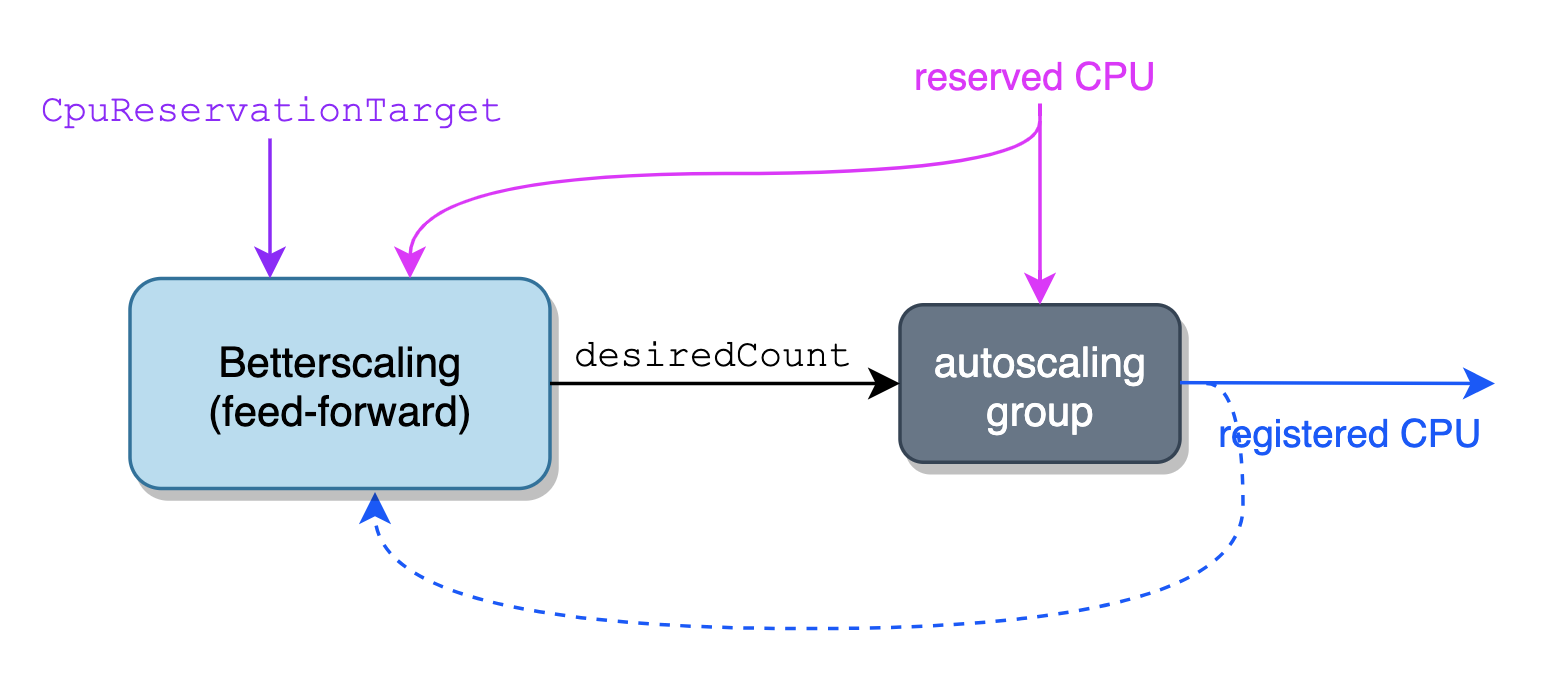
At its core, Betterscaling is a simple feed-forward control loop. On each iteration, it calculates how much total CPU capacity a cluster should have based on its current CPU reservation (fetched from the ECS API) and a target reserved percentage, and updates the DesiredCapacity on the ASG accordingly. Since Betterscaling defers to the ASG to actually scale the cluster, it’s not limited to a single availability zone.
On the surface, this is similar to running AWS autoscaling with the CPUReservation metric. However, while both are configured to target a percent CPU reservation, Betterscaling does not depend on the current percentage reservation of the cluster at all, and instead deals internally with CPU capacity in absolute terms.
Since Betterscaling has no need to rely on CloudWatch and its inherent latency, it can respond to changes in demand much more quickly than AWS autoscaling can. Additionally, its feed-forward control loop is more stable than autoscaling’s feedback loop.
Betterscaling consists of a single binary executable, with no state other than what’s stored in RAM, and just four classes comprise the majority of the source code:
DesiredCapacity for that group.To understand exactly what all this means, it’s helpful to be familiar with a few basic concepts from control theory. So, before we dive deeper into the mechanics of Betterscaling, let’s pause for a quick overview of control theory and its terminology.
Control theory describes a model where a controller continuously manipulates a dynamic system called a plant, such that the plant’s output, or process value, matches a static input to the controller called the setpoint. The plant is external to the controller and functions as a black box from the controller’s perspective, which means that the controller cannot directly affect the plant’s output. Instead, it controls it indirectly by passing an input to the plant called the control value.
The controller runs on a continous loop: on each iteration, it calculates a new control value and feeds it into the plant.
In a feed-forward controller such as Betterscaling, this calculation uses only the set point and perhaps some data external to the control system (in Betterscaling’s case, the cluster’s reserved CPU from ECS).
By contrast, a feedback controller relies on the process value output by the plant during the last iteration of the loop in order to calculate the control value for the next iteration. It determines the difference between the setpoint and the process value, referred to as the offset error or just error, and integrates that into its calculation for the new control value.
Betterscaling’s controller actually does utilize feedback from the plant, and thus is not a pure feed-forward system. However, the impact of the offset error on its output is minimal, and Betterscaling would still function adequately on feed-forward input alone.
Put together, the system (as it applies to Betterscaling) looks something like this:
control value
setpoint ╭────────────────> + ∑ ───────────────> plant ──╮
─────────────────┤ + (desired total (ASG) │
(sum of capacity │ error ^ CPU capacity) │
requested by ╰─> + ∑ ───────> ∫ ──╯ │
all hosts / - │
target percent ^ process value (feedback) │
CPU reserved) ╰───────────────────────────────────────────╯
With Betterscaling, the setpoint, control value, process value, and error are all the same kind of unit: the total number of CPU shares (either current or desired) in the cluster. In the following sections, I’ll refer to this unit as registered CPU, or RegisteredCPU when referencing a specific value in the code.
controller.go)The heart of Betterscaling, the controller is a generic algorithm that takes as input a setpoint (feed-forward input from the setpoint-setter) and a process value (feedback input from the plant), both in terms of registered CPU, and generates a control value that is used by the plant to set DesiredCapacity on the ASG.
The controller also features a mechanism to control how quickly to correct the offset error, called IntegrationTime. On each iteration, the controller adds error / IntegrationTime to the control output, rather than the full error amount. Thus, a smaller value for IntegrationTime corrects offset error more quickly, and a larger value averages error over a longer time.
Because the controller is generic, it doesn’t have any inherent notions about what kind of plant it’s working with — in fact, it doesn’t maintain a reference to the plant at all. Consequently, the controller is extremely small: excluding comments, it is only 56 lines long.
plant.go)In control theory, a plant is any system which takes an input that can be determined by a controller, and generates an output that can be used as feedback for that controller. Betterscaling’s plant represents the cluster that is being autoscaled, and is responsible for updating DesiredCapacity on the cluster. It’s even smaller than the controller, clocking in at only 38 lines of code, and it has just two methods:
SetControlOutput sets DesiredCapacity on the ASG, which triggers ECS to scale the cluster up or down as appropriate. It takes as input the control value generated by the controller, in terms of registered CPU, and is responsible for calculating how many instances we need based on that value (rounding up when scaling out, and down when scaling in).ProcessValue returns the plant’s process value, to be used by the controller. This is simply the current RegisteredCPU of the cluster, pulled from the plant’s internal reference to the cluster summarizer.aws.go)The longest of the four files, this code is responsible for querying the ECS API to fetch all the data necessary for the control loop. Any failures (rate limiting, network timeouts, etc) that could happen when interfacing with AWS happen here, before the control loop is executed. This ensures that the control loop won’t need to deal with unexpected network errors or delays.
Both the plant and the setpoint-setter hold an internal reference to the cluster summarizer. The plant uses this reference to obtain the process value, while the setpoint-setter uses it to calculate the setpoint. Both values are then fed into the controller.
setpointer.go)The setpoint in Betterscaling isn’t really static. Rather, it depends on the current reserved (not registered) CPU in the cluster, so it changes as containers are spun up or down.
Like AWS autoscaling with CPUReservation, Betterscaling is configured with a percentage of reserved CPU that it tries to target, referred to as CpuReservationTarget. We can get this value much closer to 100% than we could with AWS, but still not all the way there — it’s effectively bounded by the CPU requirements of our largest container, since we need to ensure that we have enough capacity available to place at least one new instance on each host.
The setpoint-setter (or setpointer, for short) grabs the cluster’s current reserved CPU from its internal reference to the cluster summarizer, then divides it by CpuReservationTarget in order to determine the setpoint. For example, we usually have CpuReservationTarget configured to something like 0.9, signifying 90% CPU reservation. So if the cluster’s ReservedCpu is currently 10,000, the setpoint would be 11,111, which is the total registered CPU we would need in order to hit 90% CPU reservation.
The setpointer also records a configurable number of past ReservedCPU values, and uses the largest of those in its calculation. The effect is that scale-up happens immediately, but scale-down happens only after a sustained decrease of at least that many iterations of the control loop. This is important because tasks can occasionally be terminated before new tasks have been launched to replace them, which creates a transient dip in reserved CPU. Thus scaling down immediately would not be productive; in fact, it can even be dangerous, since if that scale-down creates another dip in reserved CPU, it could potentially create a positive feedback loop that would make the control loop unstable.
Like all software, Betterscaling is still a work in progress, and it wouldn’t be quite fair to discuss it at length without diving into some of its shortcomings. With an eye toward the future, let’s wrap up by discussing how Betterscaling could be made even better.
Betterscaling lacks a control interface, which makes it harder to support and maintain than AWS autoscaling. Ideally, the process would serve a web console that shows all the controllers running and their setpoints, with a big red button that would allow us to easily stop execution if anything goes wrong.
And, speaking of things going wrong, there’s still a lot we could do to make Betterscaling more robust in the face of failure scenarios like outages. One of the benefits of Betterscaling over AWS autoscaling is that it’s much more aggressive about scaling down, but occasionally this is not ideal. During an outage, for example, we probably want to avoid scaling down when utilization is low, but the only way to do so right now is through manual intervention. Having safeguards in place that would help automate these decisions for us would be a welcome addition.
Betterscaling operates exclusively on CPU reservation. This works well for most, but not all, of our use cases — for example, we have a few services whose memory needs far exceed their CPU needs (such as our rostering service, which allows school administrators to import students, teachers, and classes into Remind from their school or district’s SIS), and we’ve had to configure these very carefully to avoid underprovisioning on memory when scaling on CPU.
Fortunately, since Betterscaling’s controller is generic, we wouldn’t need to reinvent the entire wheel to support scaling on metrics other than CPU reservation: we’d only have to implement a new plant and setpointer, and update our summarizer to query ECS (or perhaps a different service, like EC2 or SQS) for the new metric. Taking this even further, we might someday be able to use Betterscaling to scale services in addition to scaling our cluster — for example, by launching or terminating SQS workers based on the size of their queue.
While Betterscaling is already substantially more efficient than AWS autoscaling for our use cases, it’s still limited by the fact that the ECS API can’t tell you the total CPU requested by all tasks that should be running, only the CPU requested by tasks that are running. Consequently, the cluster must be scaled such that if any service scales up, it can place at least one task, and placing that task will trigger a scale up.
We touched on this limitation earlier when discussing the setpoint-setter, but it bears repeating here because it imposes a hard constraint on the maximum CPU utilization we can target: it must still be low enough that our heaviest task will always be able to fit on a host. (As of this writing, that would be our API monolith, which uses about 6% of the CPU capacity of a host.) If ECS reported utilization above 100%, or if we could detect tasks that won’t fit in our cluster and scale accordingly, we could set our utilization target even higher.
One potential solution would be to use an ECS capacity provider like Fargate to handle overflow tasks. This would allow us to target close to 100% utilization, but the extra efficiency comes at a cost. Most of our tasks need access to shared services, like pgbouncer, running locally on the same host. Tasks running on a capacity provider won’t be able to access the shared services running on our existing hosts, so we would need to sidecar those services in order to deploy to Fargate. This would require additional work to implement and inflate the cost of running overflow tasks on Fargate (which is already more expensive per CPU share than regular ECS clusters).
It can often be difficult to gauge whether it’s worthwhile to build an in-house tool to solve a problem. On top of the initial time investment to build the tool, in-house solutions must be maintained as long as they are in use, and new developers need to be trained to work with the system. (Case in point: there’s a good chance a new hire at Remind will know how to work with AWS autoscaling, but a roughly 0% chance they’ll already be familiar with Betterscaling.)
Betterscaling mitigates this risk in several ways. First, it’s small and simple, so it was quick to build and should be relatively easy to for future maintainers understand. Second, because of its feed-forward design and usage of the ECS API rather than CloudWatch, it’s able to operate reliably at a speed that AWS autoscaling simply can’t match.
Earlier, I mentioned that we still use AWS autoscaling on all of our clusters, including the one that runs Betterscaling. It’s configured no differently on this cluster than it was before we implemented Betterscaling, but these days, it almost never has anything to do: Betterscaling responds faster than AWS autoscaling can, and consistently keeps CPU reservation within the target threshold.
![]()
A snapshot of Betterscaling’s performance on a typical Thursday and Friday. The grey area is actual reserved CPU, the yellow line is the control output from Betterscaling’s controller (the target registered CPU), and the purple line is the process, or feedback, value (the registered CPU reported by ECS).
Of course, the ultimate proof is in the numbers: with Betterscaling running on our largest cluster, we’ve been able to save over $100k in provisioning costs since November 2020. These savings allow us to operate more sustainably even as we continue to grow, and help ensure that we’ll always be able to keep Remind free for the millions of teachers, students and parents who depend on it. Better scaling, better savings, better service.
