
Transitive Closure in PostgreSQL
At Remind we operate one of the largest communication tools for education in the United States and Canada. We have...

Today, Remind is open sourcing our self-hosted PaaS called Empire. Empire provides a 12 factor-compatible, Docker-based container cluster built on top of Amazon’s robust EC2 Container Service (ECS), complete with a full-featured command line interface.
Why build Empire when Heroku already exists (and works well for so many)? Well, here’s the story of why we decided to move off of Heroku, the challenges we encountered along the way, and how we built Empire as a solution for making the migration to Amazon ECS as painless as possible.
Back in 2011, Remind started as a single monolithic Rails app, hosted on Heroku. Things were simpler then: one app with a couple of dynos was more than enough to handle our trickle of traffic. We chose Heroku because it allowed us to focus on building product rather than building infrastructure, which was important when we were under 10 people. Looking back, that was one of the best decisions we ever made.
Things look a little different today. We have over 50 employees and 25 million users, and our product is now comprised of about 50 backend services — some core to the product and others built by various teams to support their efforts. In order to handle the scale that we’ve achieved, we have over 200 dynos powering all of these applications.
And we’ve learned that our growth patterns are, in many ways, unique. Because we build a product for teachers, we grow massively during back-to-school season, when we add over 350,000 new users and send over 5 million messages per day, with heavy spikes every 30 minutes.
We started to realize that if we wanted to build the architecture that we needed to support our growth, we might not be able to do it on Heroku. The primary problems we encountered were:
About six months ago, we started talking about how to migrate off of Heroku. We made a list of requirements and nice-to-haves:
We started surveying the landscape of open source platforms that supported Docker. We didn’t want to build something if we didn’t have to. At the time, the two most promising projects were Deis and Flynn. For multiple reasons, our team wasn’t comfortable putting either of these projects into production. Flynn was not at a stable release, was undergoing a significant amount of architectural changes, and had a completely custom load balancer instead of using an existing stable solution like HAProxy, Nginx or ELB. We tried Deis briefly but ultimately decided that it was more complicated than we felt it needed to be. We also weren’t aware of any companies that had put either of these projects into production at the scale that we’re at.
Based on our requirements, a small team of engineers at Remind started working on Empire. We took ideas from Flynn and Deis, as well as other projects like Netflix’s Asgard and SoundCloud’s Bazooka. Initially we chose to build on top of CoreOS, using fleet as the backend that would schedule containers onto the cluster of machines, but we made the early design decision to make the scheduling backend pluggable. We had a custom routing and service discovery layer using nginx configured via confd and registrator. This all worked out really well, until we started testing failure modes: we ran into a lot of issues with the fragility of etcd (this was when etcd was at 0.4) and bugs in fleet, and we hadn’t solved problems like zero downtime deployments.
It became clear that we would need a better scheduling backend than fleet. We started investigating Kubernetes but we were put off by the need to run a network overlay, and we really didn’t want to have to run and manage our own clustering.
Trying to piece together this many new and rapidly changing projects into a production-grade PaaS proved to be an exercise in frustration and futility. It was clear that we had to take a step back and simplify, removing as many unstable components as possible.
Coincidentally, Amazon ECS was made generally available around this time, and it immediately became apparent that it would solve almost all of the problems we had encountered:
After some initial research and prototyping, we swapped our scheduling backend to Amazon ECS. Each process defined in a Procfile would be directly mapped to a “Service” within Amazon ECS. Because Amazon ECS integrates with ELB, we also decided to remove our custom routing layer in favor of attaching ELBs to the web processes of an app. This raised the question of how we would solve service discovery within the system. We opted to use a private hosted zone in Route53 and create CNAMEs pointing to the ELBs for each applications web process. We use DHCP option sets to set the search path on hosts to .empire so services need only know the name of the app they want to talk to (e.g. http://acme-inc). We were able to eliminate many of the moving parts in the system, like etcd; our cluster hosts were now bare Ubuntu machines with Docker and the Amazon ECS agent on them.
For our architecture, this system has worked very well. We have a “router” application attached to an internet-facing ELB (in Empire, an application is internal by default, but can be exposed publicly by adding a domain to it).

This app runs nginx with openresty and routes to the appropriate private applications, whether that is our API, Web dashboard or another service. It also handles request id generation so we can trace requests as they move from service to service. The big win here is that our router is now managed in exactly the same way as any other application in Empire; it gets deployed the same way, gets configured the same way, and it can easily be spun up in development with a simple docker run remind101/router. In the future, this could even be replaced by something like Kong.
Today, Empire is an easy-to-run, self-hosted PaaS that is implemented as a lightweight layer over Amazon ECS. It implements a subset of the Heroku Platform API, which means you can use the hk or heroku CLI clients with it, or our emp CLI. Here are a couple of examples of how easy Empire is to use.
Deploying a new application from the docker registry is as easy as emp deploy <image>:<tag>:
$ emp deploy remind101/acme-inc:latest
Once we’ve deployed the application, we can list our apps:
$ emp apps
acme-inc Jun 4 14:27
And list the processes that are running:
$ emp ps -a acme-inc
v2.web.217e2ddd-c80c-41ed-af16-663717b08a3f 128:20.00mb RUNNING 1m "acme-inc server"
We can scale individual processes defined in a Procfile:
$ emp scale worker=2 -a acme-inc
$ emp ps -a acme-inc
v2.web.217e2ddd-c80c-41ed-af16-663717b08a3f 256:1.00gb RUNNING 1m "acme-inc server"
v2.worker.6905acda-3af8-42da-932d-6978abfba85d 256:1.00gb RUNNING 1m "acme-inc worker"
v2.worker.6905acda-3af8-42da-932d-6978abfba85d 256:1.00gb RUNNING 1m "acme-inc worker"
And even explicitly limit the CPU and Memory constraints:
$ emp scale worker=1:256:128mb -a acme-inc # 1/4 CPU Share and 128mb of Ram
We can list past releases:
$ emp releases -a acme-inc
v1 Jun 4 14:27 Deploy remind101/acme-inc:latest
v2 Jun 11 15:43 Deploy remind101/acme-inc:latest
And also rollback to a previous release in a matter of seconds:
$ emp rollback v1 -a acme-inc
Rolled back acme-inc to v1 as v3.
All of this is happening inside infrastructure that we have control over.
Empire is not at 1.0 yet (0.9.0 at the time of this post), but we’ve been running most of our applications and services within Amazon ECS managed via Empire for the last few weeks now and have found it to be incredibly stable. Performance of these services has significantly improved as we’ve moved them from Heroku to Empire. On average, we’ve seen a 2X decrease in response times in the 99th percentile, with less variance and fewer spikes. Here are a couple examples:
This graph shows response times for our files service as seen from our API (RTT) when we moved it from Heroku to Amazon ECS.
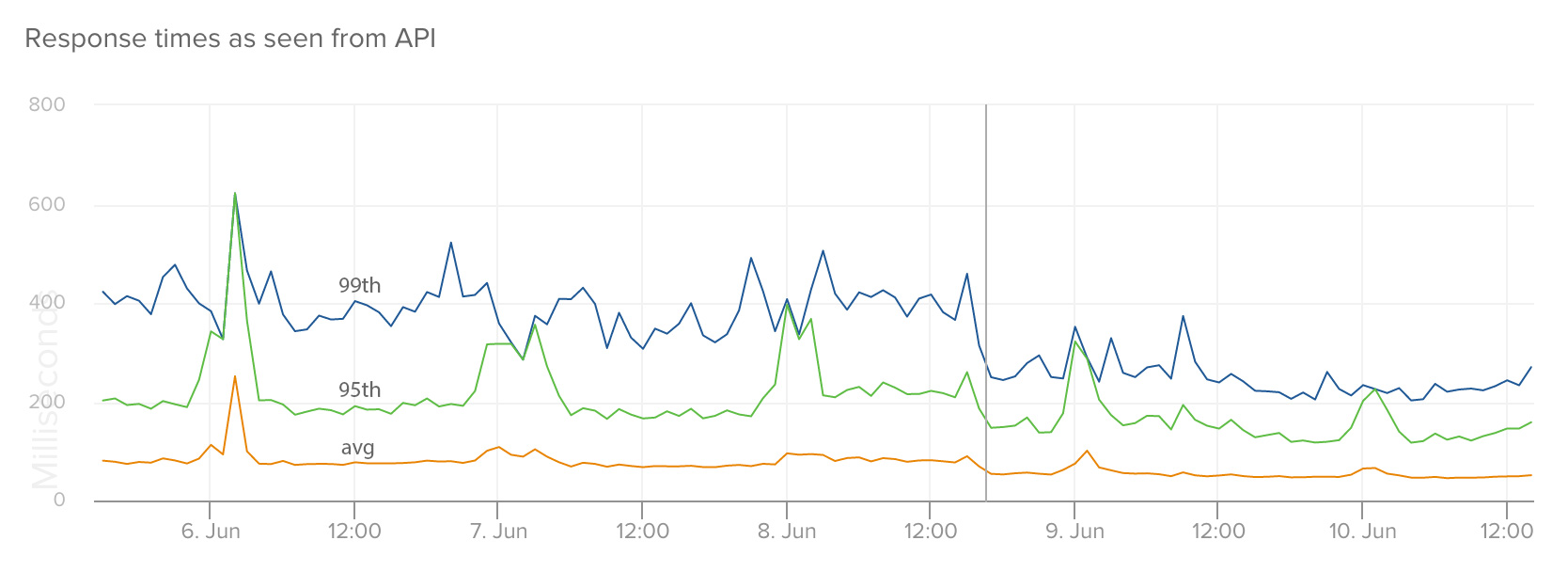
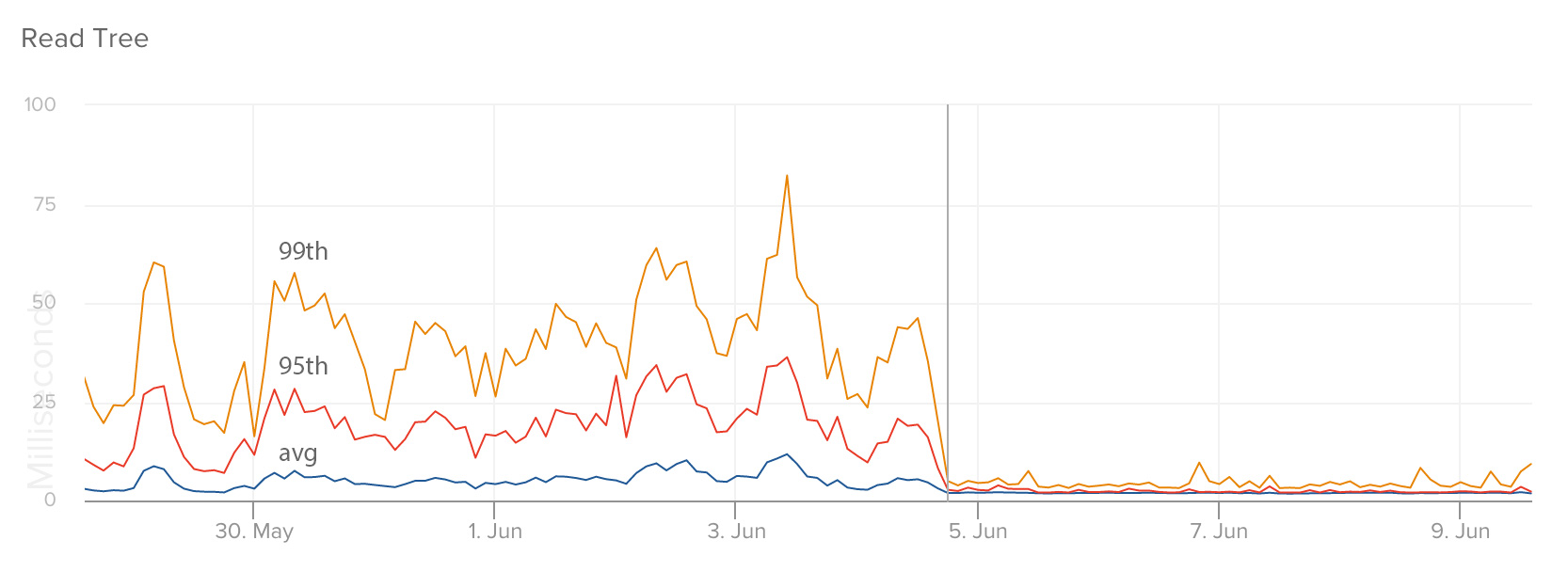
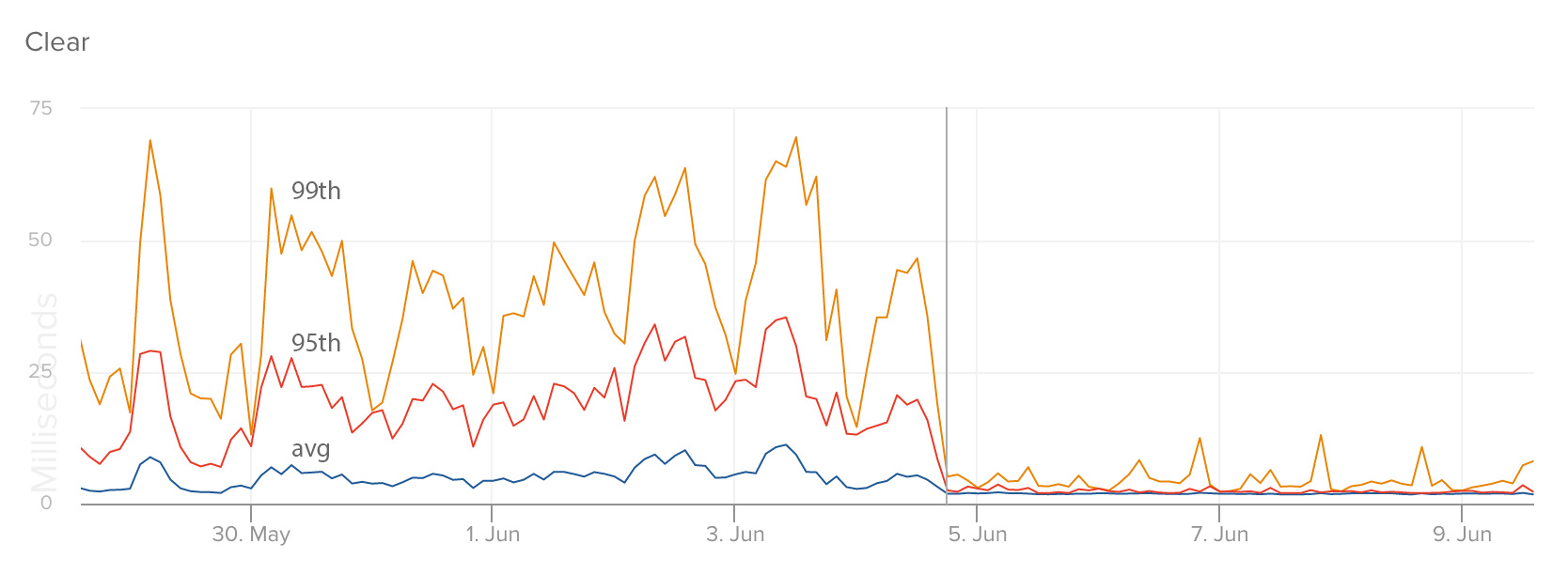
These graphs show response times of specific endpoints in our service that manages a user’s number of unread messages:
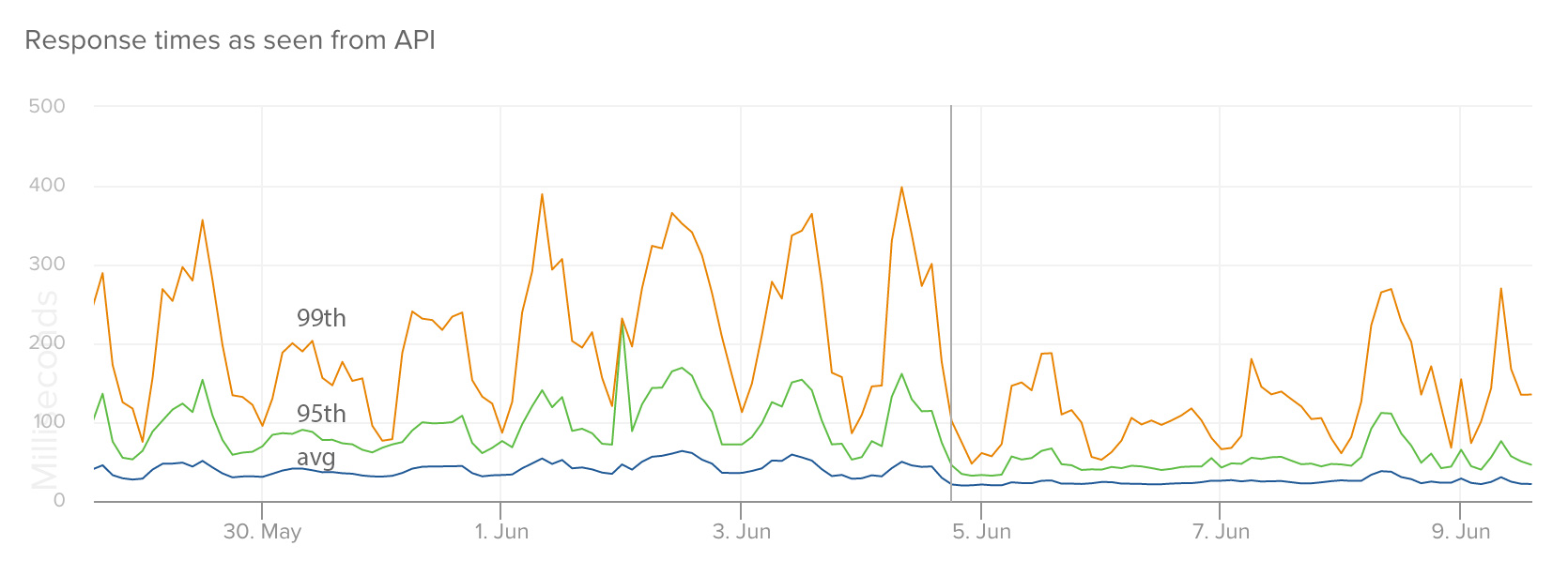
And the change in response time as seen from our API (which was still running on Heroku at the time; we expect this to drop even further, and flatten out, when we move it to Empire):
That depends. If you’re a small startup, honestly, you should just be using Heroku, as it’s the easiest way to deploy your application. Empire doesn’t come for free; you’ll still need to build your own logging and metrics infrastructure (which I’ll be writing about in a future post) and Empire is still under active development. We’re huge fans of Heroku and will continue to run smaller applications that aren’t core to our product there. But if you begin to run into the same limitations that we did, then our hope is that Empire provides a nice stepping stone for your infrastructure, as it has for us.
Ultimately, we like to build simple, robust solutions to problems at Remind. While we’re never afraid to play with the “hot new stuff,” we see value in stable technologies that just work, that don’t wake us up in the middle of the night. Most of our platform is built on these stable technologies, like nginx, postgres, rabbitmq, and ELB, and Amazon ECS has proven to be incredibly stable despite its recent release.
If one thing is for certain, it’s that the domain of container based infrastructure is changing rapidly. What we are capable of building now, would not have been possible 1-2 years ago, thanks to projects like Docker and Amazon ECS, and it’s likely that the landscape will look completely different in the coming years as containerization becomes more common.
We still have big plans for Empire, like the ability to attach load balancers to any process (not just the web process), extended Procfiles so you can configure health checks and exposure settings in source control, and sidekiq containers so you can run something like statsd or nginx in a linked container. Our hope is to eventually also support Kubernetes as a scheduling backend.
Overall, our entire team is excited about the results so far and about moving forward with Empire and Amazon ECS, and we’re open sourcing it in the hopes that it will be useful to other people.

